Foreword
The only slightly odd thing about this marvellous and indispensable document (with lots of other fine goodies on the same site) is the title, with its use of the terms "tutorial" and "reintroduction". People with little or no knowledge of XML who went there might soon wander off again in puzzlement. And experienced XML practitioners might not look at the site at all, expecting it would be too elementary for them. You do need to know XML quite well to make much sense of what Mike offers; but even if you know XML very well indeed, Mike has things to say about encoding that you almost certainly either don't know at all, or haven't yet fully grasped. If only everyone writing XSLT processors, for example, had taken everything Mike says on board from the start, there would be a lot less encoding and transcoding headaches forever recurring on the relevant lists. A further point, which is not Mike's problem, but a general cultural issue. He uses a few key terms ("abstract", "mapping" etc) in a precise mathematical/comp. sci. way, and unless you understand those precise senses you won't fully follow what he is saying. Since I'm writing for people with a Humanities background, I have regrettably to sound that warning, because so many people in the Humanities foolishly pride themselves on their militant ignorance of basic mathematical terminology and concepts Where would we be if scientists took the same view? If I'm writing a review for the TLS, I naturally avoid some of the more technical linguistic or analytical vocabulary I freely use when writing an article for a scholarly journal. But I'd be very surprised if the TLS editor complained because my copy used hard words like "narrator", "sonnet" or "parody" that a "general reader" couldn't possibly be expected to understand. None of Mike's use of "technical" vocabulary in this piece goes beyond the analogous domain in his own area of expertise, so if you don't understand his terms, educate yourself rather than giving up or complaining. You know it makes sense!
Introduction
This is a crash course in some essential concepts for software developers who are reading and writing XML documents on a regular basis. It is oriented toward people with some sort of programming background. The intended audience should already understand some basic things like what bits and bytes are, how to read hexadecimal numbers, what characters are, and they should be comfortable with phrases like "hierarchical data model".
I wrote this document after having the realization, in early 2000, that every published XML reference I have seen does not adequately explain some fundamental concepts that, in my opinion, are essential to understand before trying to do any serious development with XML. It might seem strange that examples of how to write an XML document are not introduced until well into the tutorial. I feel strongly that the proper way to learn this material is to understand the founding concepts and principles first. Then the details of the syntax become almost incidental.
1. Characters, The Unicode Standard, and ISO/IEC 10646-1
Why you need to know this: XML is specified in terms of allowable sequences of "characters" as defined by the ISO/IEC 10646-1:1993 international standard, which is almost, but not quite, the same thing as The Unicode Standard version 2.0.
1.1 Graphemes and characters
In written languages, a grapheme is an unit, expressed as some kind of mark, that conveys basic information essential to the language. Letters, numbers, punctuation and diacritics are examples of graphemes found in the Latin script (component of a writing system) that is used to write in English, French, Spanish, German, Vietnamese, and various other languages. Graphemes are abstract concepts; any time you write or see the capital letter "A" rendered on paper or on your computer screen, you recognize it as being the same grapheme — the letter A — regardless of the font or handwriting or medium in which it is written. The actual marks you see are allographs, or glyphs, that represent the "A" grapheme.
In computing and telecommunications, dividing the basic marks of a writing system into graphemes is helpful, but is not sufficient, on its own, to reproduce written text, since there is more to writing than just spewing a stream of graphemes. Therefore, in these contexts, graphemes are represented by abstract units called characters. For example, the capital letter "A" is a grapheme that, in computing and telecom, is represented by the capital letter "A" character.
Characters don't always represent things that people who study writing systems would consider to be true graphemes. For example, instead of representing an individual grapheme, a character might represent a particular combination of graphemes: the small letter "e" grapheme with a grave accent grapheme over it, "`", can be, in computing and telecom, a single "small e with grave" character, "è".
Characters can also embody other units that are not graphemes. For example, in the Latin script, we need to put space between words. In the other scripts, such space isn't necessary, although the concept of word separation is still useful. So there exist special characters that represent different kinds of word, line, and paragraph separators and/or literal, visible space. There are also special characters that don't manifest in writing at all, but are rather just exist in order to convey instructions to a mechanical device (tab, line feed, carriage return, and form feed characters, for example) or to provide hints for interpreting or rendering subsequent characters.
 1.2. The Unicode Standard
1.2. The Unicode Standard
The Unicode Standard is a character coding system designed to support the interchange, processing, and display of the written texts of the diverse languages of the modern world. It is a product of The Unicode Consortium. The Unicode Consortium is a group of major computer corporations, software producers, database vendors, research institutions, international agencies, various user groups, and interested individuals.
 1.3. ISO/IEC 10646-1
1.3. ISO/IEC 10646-1
Since 1991 the Unicode Consortium has worked with the International Organization for Standardization (ISO) to develop the Unicode Standard and the international standard ISO 10646 in tandem. The character encoding portion of Version 2.0 of the Unicode Standard is identical to ISO/IEC 10646-1:1993 plus its first seven published amendments. Unicode 3.0 was published in February 2000 and its relevant portions were later adopted as ISO/IEC 10646-1:2000. Although there are newer versions of Unicode that correspond with ISO/IEC 10646-1 and 10646-2 combined, this tutorial primarily addresses the versions available prior to 2000, since XML does not reference the newer versions.
ISO/IEC 10646-1 defines and is also known as the Universal Character Set, or UCS.
1.3. The Unicode Standard vs. ISO/IEC 10646-1
In general, the terms Unicode and UCS are interchangeable because the two specifications share the following characteristics:
- They both assign the same values and descriptions to all the same characters
- They both specify the same levels of implementation
- They both use a 16-bit code space (this will be explained later)
- They both specify the UTF-8 and UTF-16 character encoding forms (this will also be explained later)
Unicode differs from ISO/IEC 10646-1 in the following significant ways:
- The Unicode Standard specifies semantics, properties and rendering algorithms for characters; ISO/IEC 10646-1 does not.
- The Unicode Standard does not acknowledge (but likewise does not prohibit) the UCS-2 and UCS-4 character encoding forms found in ISO/IEC 10646-1. (explained later)
- The Unicode Standard is a relatively affordable printed publication that can be purchased through any bookseller and is supplemented by many online materials at http://www.unicode.org/. The entire Unicode Standard itself is also now available online, but ISO/IEC 10646-1 is an expensive printed publication that can only be purchased through ISO partners and has no online edition.
There are a few other less significant, but still important, differences that are described in Tony Graham's excellent book Unicode - A Primer (ISBN 0-7645-4625-2). The title of this book is somewhat misleading, as it seems to be less a primer and more a technical encyclopedia, but it's still worth perusing, as it explains many aspects of Unicode in prose that is relatively easy to comprehend.
Note: Unless otherwise stated, any further references to Unicode in this document mean The Unicode Standard, version 3.0.
2. The Unicode/UCS character encoding model
Why you need to know this: XML documents consist, at a granular level, of abstract characters that have had several encoding mechanisms applied to them. In order to consistently author, store, transmit and process XML documents, there must be an awareness of the encodings that are being or have been applied.
2.1 Character names and the need for encoding
The basic idea of Unicode and the UCS is that a set of abstract objects called characters can be represented by at least one descriptive name and also by at least one unique number. The names are not canonical because they translated to many languages for different publications of the standard. The numbers are constant and canonical.
A character's number is abstract to computers because there are many different ways of representing numbers in an information processing architecture. So, Unicode and the UCS prescribe a model for information systems to store, exchange and process character data.
2.2. Character encodings - assignment of unique numbers to abstract characters
In general, a set of abstract characters is a character repertoire.
A code space is a set of numbers called code points, or code positions. These numbers are scalar values: non-negative, not-necessarily-contiguous integers.
A mapping of abstract characters from a character repertoire to code points is called a coded character set. Other names for such mappings are character encoding, coded character repertoire, character set definition, or code page. Each combination of an abstract character and its code point in a coded character set is an encoded character. A coded character set can reserve code points for special purposes other than mapping to abstract characters.
Aside from the Universal Character Set and Unicode, other popular coded character sets include the following subsets:
- The WGL4 (Windows Glyph List) defined by Microsoft and Agfa Monotype, which is a repertoire of 560 abstract characters implemented by most MS Windows fonts. It is a subset of Unicode plus two private use characters, encompassing the characters in ISO 6937 plus all Microsoft/IBM 8-bit code pages. Since WGL4 is defined as a subset of Unicode, it can be considered a coded character set.
- The AGL (Adobe Glyph List), a superset of WGL4.
(Despite being called "Glyph" Lists, they are actually character-to-code point mappings.)
Note: The "0x" notation used in this document is the C language's notation for hexadecimal numbers. (Ref: ISO 9899). It is one of many possible notations for values in a base 16 system. There is no particular reason it is being used here other than that it seems to be a fairly widely recognized convention.
Unicode and the UCS define a coded character set in which each abstract character is mapped to a
code point in the range 0x0..0x10FFFF (0 through 1,114,111 decimal). This code
space is divided into 17 planes of 65,536 (0x10000) code points each. The first plane,
encompassing code points 0x0..0xFFFF, is called the Basic Multilingual
Plane, or BMP, and it covers all of the characters in common use in all of the modern
languages of the world. It omits some less common characters as well as those that were used in arcane
scripts; those characters are in the higher planes.
The Unicode Standard calls each of the code points in the 0x0..0x10FFFF
code space a Unicode scalar value. Each Unicode scalar value uniquely identifies the
character assigned to that code point, if such an assignment has been made. There are certain ranges of
Unicode scalar values that are not assigned to characters by the standard; they are reserved for special
functions or future extension mechanisms. There are also code points that have been assigned to unspecified, privately-defined characters.
In the diagram below, each green cloud shows a code point and each beige cloud shows a character name. Each combination of code point + character name is an encoded character ("encoded" just in the sense that is has been associated with a number).
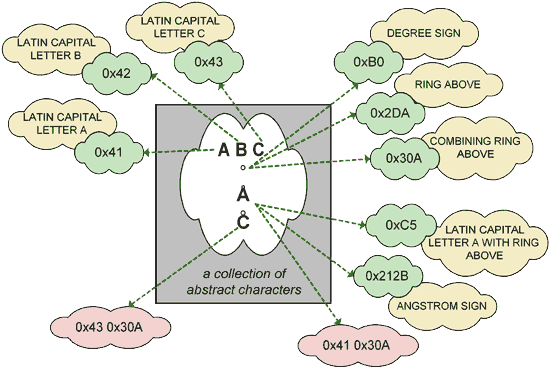
Unicode allows certain encoded characters to be combined in sequences in order to represent abstract characters that may or may not have other encoded character representations. That is, one or more encoded characters can together represent, through equivalence, a single abstract character. For example, as shown by one of the pink clouds in the diagram above, the character LATIN CAPITAL LETTER A (code point 0x41) followed by the "combining" character COMBINING RING ABOVE (code point 0x30A) are two separate characters that are not only equivalent to the single "compatibility" character LATIN CAPITAL LETTER A WITH RING ABOVE (code point 0xC5), but also to the equivalent to the single character ANGSTROM SIGN (code point 0x212B).
Here are 3 ways of representing the Unicode scalar value of the Unicode character named "ANGSTROM SIGN":
- in the C language's hexadecimal notation:
0x212B - in decimal notation:
8491 - in EBNF notation:
\v00212B
Here is a way of representing the abstract character itself, using its scalar value:
- in Unicode's deprecated "U-" notation, which requires 8 hex digits:
U-0000212B - in Unicode's "U+" notation, which requires 4 to 6 hex digits:
U+212B
Note: using the "U+" notation to represent a character by its code point is a convention introduced in Unicode 3.1 (most likely due to abuse of the old convention). Prior to Unicode 3.1, the "U+" notation could only be used for Unicode code values, as described below, and required exactly 4 hex digits.
In prose, the "U+" notation is the preferred way of referring to characters.
2.3. Encoding forms and code values - conversion of abstract character numbers to sequences of numbers that data processing devices can manipulate
Code values, or code units, are numbers that computers use to represent abstract objects and concepts like Unicode characters. Like code points, code values are typically non-negative integers, but code values usually only manifest in a fixed 8 bit, 16 bit, or 32 bit width. An encoding form is the mapping of a code point representing an abstract character in a coded character set to a sequence of one or more code values.
ISO/IEC 10646-1 defines a 32-bit encoding form called UCS-4, in which each encoded
character in the UCS is represented by a 32-bit code value in the code space 0x0..0x7FFFFFFF
(the most significant bit is not used). This encoding form is sufficient to represent all
0x10FFFF Unicode scalar values and then some. Some people consider this
wasteful to reserve such a large code space for mapping a relatively small set of code points, so
a new encoding form, UTF-32, was proposed. UTF-32 is a subset of UCS-4 that uses
32-bit code values only in the 0x0..0x10FFFF code space. UTF-32 became part
of the Unicode Standard in 2002, with the publication of
Unicode Standard Annex #19,
which was later incorporated into Unicode 4.0.
ISO/IEC 10646-1 also defines a 16-bit encoding form called UCS-2, in which a 16-bit code
value in the code space 0x0..0xFFFF directly corresponds to an identical
scalar value, but this form is, of course, inherently limited to representing only the first
65,536 scalar values.
The Unicode Standard and ISO/IEC 10646-1 both define two more important encoding forms: UTF-8 and UTF-16.
UTF-16 is a variation on UCS-2 that maps each Unicode scalar value to a unique sequence
of up to two 16-bit code values. In UTF-16, each 16-bit code value in the
0x0..0xD7FF and 0xE000..0xFFFF code spaces
directly corresponds to the same Unicode scalar value. A surrogate pair of 16-bit code
values from the 0xD800..0xDFFF code space algorithmically represents
a single Unicode scalar value in the range 0x010000..0x10FFFF. The
first half of the pair is always in the 0xD800..0xDBFF range, and the
second half of the pair is in the 0xDC00..0xDFFF range.
| Unicode scalar value |
UCS-4 code value sequence |
UCS-2 code value sequence |
UTF-16 code value sequence |
0x0 |
0x00000000 |
0x0000 |
0x0000 |
| | | | | | | | |
0xD7FF |
0x0000D7FF |
0xD7FF |
0xD7FF |
Unicode scalar values omit0xD800..0xDFFF |
|||
0xE000 |
0x0000E000 |
0xE000 |
0xE000 |
| | | | | | | | |
0xFFFF |
0x0000FFFF |
0xFFFF |
0xFFFF |
0x10000 |
0x00010000 |
0xD800 0xDC00 |
|
| | | | | | | |
0x10FFFF |
0x0010FFFF |
0xDBFF 0xDFFF |
|
0x00110000 |
|||
| [ n/a ] | | | ||
0x7FFFFFFF |
|||
UTF-8 algorithmically maps each Unicode scalar value to a unique sequence of one to six 8-bit code values. The mechanism used by UTF-8 is relatively complex.
XML developers should at least know that the first 256 Unicode scalar values
0x0..0xFF intentionally coincide with identical code points
and byte values in the ASCII (0x20..0x7F),
ISO/IEC 8859-1 (0xA0..0xFF), and
ISO/IEC 6429 (0x00..0x1F, 0x80-0x9F) standards.
The UTF-8 sequences for the same range are shown in this table:
| Unicode scalar value | UTF-8 code value sequence |
0x0..0x7F |
0x00..0x7F |
0x80..0xBF |
0xC2 0x80 .. 0xC2 0xBF |
0xC0..0xFF |
0xC3 0x80 .. 0xC3 0xBF |
Here are various ways to represent the abstract character named "GOTHIC LETTER QAITHRA
(=Q)", which is assigned to the Unicode scalar value 0x10335:
- as a Unicode scalar value, in Unicode's "U-" notation:
U-00010335 - as a Unicode scalar value, in Unicode's "U+" notation:
U+10335 - as a UCS-4 code value sequence, in C hex notation:
0x00010335 - as a UCS-2 code value sequence: illegal; out of range
- as a UTF-16 code value sequence, in C hex notation:
0xD800 0xDF35 - as a UTF-8 code value sequence, in C hex notation:
0xF0 0x90 0x8c 0xB5
2.3.1. Unicode values - representation of abstract characters as UTF-16 code value sequences
Starting with Unicode 3.1, the standard directly assigns abstract characters to Unicode scalar values (code points). Previous versions of Unicode only assigned each character to a sequence of 1 or 2 "Unicode values". Unicode values are the code value sequences produced by the UTF-16 encoding form.
In order to retain backward
compatibility with earlier versions of Unicode, Unicode 3.0 and ISO/IEC 10646-1:2000
adopted the UTF-16 encoding form as the basis for Unicode values, making UTF-16 the
only official usage of the 0xD800..0xDFFF scalar range.
Prior to version 3.1, Unicode prescribed a "U+xxxx" notation with 4 hex digits to designate a
Unicode value in printed literature. A Unicode value sequence is considered equivalent to the
abstract character it represents. Since these Unicode values were UTF-16 code values, encoded
characters with scalar values in the 0x0..0xFFFF range were represented
with one U+xxxx designation, and encoded characters with scalar values in the
0x010000..0x10FFFF range were represented with a pair of
U+xxxx designations. For example, the character at code point
0x010000 was represented in the old notation by U+D800 U+DC00,
but is represented in the new notation by U+10000.
Starting with Unicode 3.1, the "U+" notation with 4 to 6 hex digits now designates a Unicode
scalar value, not a code value. Code values are now written as 4 hex digits in angle brackets,
separated by spaces when there is a sequence, like <D800 DC00>.
Unicode allows certain encoded characters to be combined in sequences in order to represent abstract characters that may or may not have other encoded character representations. That is, one or more encoded characters can together represent, through equivalence, a single abstract character. For example, as shown by one of the pink clouds in the diagram above, the character LATIN CAPITAL LETTER A (code point 0x41) followed by the "combining" character COMBINING RING ABOVE (code point 0x30A) are two separate characters that are not only equivalent to the single "compatibility" character LATIN CAPITAL LETTER A WITH RING ABOVE (code point 0xC5), but also to the equivalent to the single character ANGSTROM SIGN (code point 0x212B).
So here are three more ways to represent the abstract character named "GOTHIC LETTER QAITHRA (=Q)":
- as a Unicode value pair, in EBNF notation:
\uD800 \uDF35 - as a Unicode value pair, in Unicode 3.0's "U+" notation:
U+D800, U+DF35 - as a Unicode value pair, in Unicode 3.1's notation:
<D800 DF35>
As precise as code values are, these representations are still too abstract for a computer to work with. Computers need code values to manifest as bits & bytes in a certain order. Character encoding schemes and character maps accomplish this.
2.4. Character encoding schemes - conversion of code values to byte sequences
An algorithm for converting code values to a sequence of 8-bit values (bytes or octets) for cross-platform data exchange is a character encoding scheme. Encoding forms that produce 7-bit or 8-bit code value sequences don't need additional processing, so UTF-8, for example, can be considered to be both a character encoding form and a character encoding scheme.
Other encoding forms, however, need to have a consistent mechanism applied to convert their 16-bit or 32-bit code value sequences to 8-bit sequences. Unicode 3.0 has the character encoding schemes UTF-16BE and UTF-16LE for this purpose. These work like UTF-16 but split each code value into a sequence of one or more pairs of bytes, with each byte pair being either in Big Endian order for UTF-16BE (i.e., the byte with the most significant bits comes first) or Little Endian order for UTF-16LE.
Continuing with the example, here are representations of GOTHIC LETTER QAITHRA (=Q) as a sequence of octets that a computer can use:
- UTF-16BE bytes:
11011000 00000000 11011111 00110101 (0xD800 0xDF35) - UTF-16LE bytes:
00000000 11011000 00110101 11011111 (0x00D8 0x35DF) - UTF-8 bytes:
11110000 10010000 10001100 10110101 (0xF0 0x90 0x8C 0xB5)
2.5. Character maps (character sets) - direct mappings of abstract characters to byte sequences
A character map correlates an abstract character in a character repertoire with a specific sequence of bytes, skipping the intermediate steps of code points, encoding forms, and encoding schemes. Other words for character map are character set, charset (i.e., what is used in Content-Type HTTP and MIME headers), charmap, or sometimes code page.
Character maps are what most people envision when they speak of 'character sets'. Examples of character maps are US-ASCII, ISO-8859-1, EUC-JP, KOI8-R, to name just a few.
A note about fonts: A font is, in general, just a collection of glyphs: visual representations of characters, or the necessary instructions for drawing those characters, in a particular, often decorative, style. A glyph that represents a character is no more that character than a painting of a tree is an actual tree. TrueType font files happen to contain a mapping of glyphs to Unicode code points. This makes it easy for a Unicode-aware operating system to obtain the rendering instructions for characters according to their code point.
3. XML document character syntax
Why you need to know this: In order to author XML documents, one must understand what sequences of what characters are allowed in an XML document, and how to find and interpret the syntax rules that are defined in the spec.
3.1. How to read the syntax rules in the XML 1.0 Recommendation
An XML document is a UCS character sequence that follows certain patterns. These patterns provide a means of representing a logical hierarchy (a tree) of data.
The XML 1.0 Recommendation establishes conventions for using certain UCS character sequences to represent data and certain other UCS character sequences to represent markup. The markup allows the logical hierarchy to be expressed in the document along with the data itself.
The Recommendation defines these conventions partly with prose explanations and partly with a formal grammar written as a set of "productions" in Extended Backus-Naur Form (EBNF) notation. This notation is described briefly in section 6 of the spec. It is helpful to know how to read the EBNF productions because they are the definitive reference for proper syntax.
The EBNF productions do little more than enumerate allowable UCS character sequences. Basic sequences are assigned to symbols, which in turn are the foundation for more advanced combinations of symbols and other character sequences. These sequences build upon each other to the point where an entire XML document can be expressed with the following EBNF production:
document ::= prolog element Misc*
This production says that the symbol named document (which represents a well-formed XML
document), consists simply of one prolog followed by one element followed by zero or more
Miscs. Each of these symbols is defined in terms of other symbols and character sequences.
Note that the XML 1.0 Recommendation refers to UCS characters by their Unicode scalar
values, using a notation of #x followed by only as many hex digits as
needed. So #x9 in the EBNF productions means the abstract character
that would be represented in Unicode 3.1's "U+" notation as U+0009. It does
not necessarily mean a byte with hex value 9.
Char ::= #x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF]
S ::= (#x20 | #x9 | #xD | #xA)+
The first line means that Char is the one character that is in those ranges listed.
Note that characters U+0000 through U+0008
and several other ranges are not considered Chars and are not allowed in XML documents.
The second line shows that S is a sequence of one or more instances of any of the 4
"whitespace" characters. The definition of a Comment is given as:
Comment ::= '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->'
This means that Comment is the 4 characters <!-- and the 3 characters -->, in between which are 0 or more instances of either a Char that is not -, or the character - followed by a Char that is not -.
Misc ::= Comment | PI | S
This means that Misc is one of Comment, PI, or S.
The definition of PI is too lengthy to include here, so we'll just leave it
as it is.
Since Comment and S have been defined, it would be just as accurate to say:
Misc ::= '<!--' ((#x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF] - '-') | ('-' (#x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF] - '-')))* '-->' | PI | (#x20 | #x9 | #xD | #xA)+
The other components of document are defined in the same way. It follows that a well-formed XML document is a UCS character sequence that follows certain patterns.
3.2. XML document syntax and character encoding forms
XML documents, in order to be stored or transmitted, must manifest in an encoded form as bits and bytes, using a consistent character encoding mechanism such as UTF-16 or UTF-8.
When these "physical" documents are assembled or modified, care must be taken to ensure that encodings are consistently applied. If one encoded document is pasted into the middle of another that has a different encoding, the resulting byte sequence could represent corrupted data or could even be unparsable.
The XML 1.0 Recommendation requires that any software that reads XML documents and provides access to their content and structure must be able to support both UTF-8 and UTF-16 encoding forms. The spec further dictates that if UTF-16 encoding is used, a byte-order mark must be present at the beginning of the document. If no hints to a document's encoding are available, it is assumed that UTF-8 encoding is in effect, and it would be an error if the document were not actually encoded with UTF-8.
Because in Latin-based languages the majority of the characters needed in an XML document
come from the US-ASCII range (U+0000 to U+007F), UTF-8 is usually the most suitable encoding.
UTF-16 may be more straightforward to implement, but it is difficult to compose UTF-16 encoded
documents with most text editing software, and it is wasteful to use 2 bytes per character when
most characters fall in a very small range. UTF-8 is also advantageous because the XML spec
requires that it be the assumed encoding when the document contains no other cues as to its
encoding.
3.3. Parsing - decoding and interpreting an XML document
Interpretation of an XML document's logical contents cannot begin until the encoded document has first been decoded into a sequence of UCS characters. Since UCS characters are intangible, decoding, to a computer, really means conversion to some other encoding form, most likely UTF-16, UCS-2 or UCS-4.
Decoding a document, comparing it to the EBNF productions, and interpreting its logical contents in a consistent manner is the job of a software application called an XML processor, also commonly referred to as an XML parser. An XML parser feeds the logical contents to another application that makes use of that info in some way. SAX (Simple API for XML) is a de facto standard that defines a convention for parsers to report the logical contents to an application.
4. XML document entities
Why you need to know this: The term 'entity' is ubiquitous in XML, but has a very specific meaning. It is important to understand and distinguish between entities, entity references, character references, and character entities.
The XML 1.0 Recommendation states that an XML document can be divided into sections called entities. Each entity can exist in a different place —a block of memory or a file on a disk, for example. The entity that contains the main body of the document is the document entity.
If an entity consists of XML character data (i.e., it is a fragment of an XML document), it is called a parsed entity. An XML parser combines the document entity and parsed entities into a contiguous sequence of UCS characters. As it reads a document entity, it locates, decodes, and imports the contents of each parsed entity as replacement text that replaces references to that entity. Parsed entities can have their own character encodings.
An entity that contains non-XML data of any kind (e.g., a binary file like a JPEG or MP3) cannot be read by an XML parser and is therefore called an unparsed entity. An XML document can contain information about the location and format of an unparsed entity, and it can refer to the entity, but it cannot actually contain the entity itself. An XML parser does not replace a reference to an unparsed entity; it just passes the info about the entity to the application. Unparsed entities can only be referred to in limited contexts and are not particularly useful.
The XML 1.0 Recommendation requires that entities be declared in the Document Type Definition (DTD), which is a special part of an XML document's logical structure where document validity constraints are declared. A required part of the DTD, the internal subset, exists in the document entity. An optional part of the DTD, the external subset, may exist in an entity that is external to the document entity.
An entity that is only for use in the document is a general entity. An entity that is for use only within the DTD is a parameter entity. Parameter entities are useful as macros for often-repeated text that is used in a DTD, or to represent pseudo data types.
An entity is either internal or external. If the declaration of an entity identifies the entity's replacement text by its location (a URI), or if the entity is unparsed, then the entity is said to be external. If the declaration of an entity includes its replacement text (either with literal characters, entity references, or both), then it is said to be internal.
Due to the limitations on unparsed entities, the actual combinations of characteristics of a given entity are as follows:
- Internal parsed general
- Internal parsed parameter
- External parsed general
- External parsed parameter
- External unparsed general
When a parsed entity is declared in a DTD, it is given a name. This name is the basis of
references to that entity. The syntax of an entity reference is the UCS character sequence
&name; for general entities, and %name; for parameter entities.
There are 5 built-in internal general parsed entities that all XML processors must recognize, even if they have not been declared in a DTD. These entities are used to escape character data that is not markup.
| Built-in entity reference | Replaces character |
& |
& |
< |
< |
> |
> |
" |
" |
' |
' |
An XML parser that is not validating an XML document is not required to read any external entities, so in some situations it is not an error for a document to refer to an entity that is declared in one of those entities. This depends on whether the document declares itself as being "standalone", which means that it does not have markup declarations (including entity declarations) in any external entities.
In addition to entity references there are character references, each of which refers to
one UCS character by its code points. The syntax of a character reference is the same as for
general entities, but instead of a name, the character is identified by its code position, in
the form #xABCD for hex or #1234 for decimal. For example,
  or   are both references to U+00A0,
the non-breaking space character.
The term character entity is not defined by the XML spec, but since character reference
and entity have definite meanings, one can infer that a character entity is a general entity that
has a single character as its replacement text. The five built-in entities can be considered
character entities, but a numeric character reference like   is not an
entity at all, so it cannot be called a character entity.
There are restrictions on what UCS characters are allowed in a parsed entity. Certain
characters are disallowed, and cannot even be referenced via character references. The allowed
characters are:
U+0009 (tab), U+000A (linefeed), U+000D (carriage return),
U+0020through U+D7FF, U+E000 through U+FFFD, and
U+10000 through U+10FFFF.
Consequently, a parsed entity is not a good place to store arbitrary binary data, unless the
data is pre-encoded with the Base64 or uuencode mechanisms.
5. XML logical structures
Why you need to know this: This is the heart of XML; one must think of XML not just in terms of its literal, lexical structures, but also in terms of the logical, implied structures that the document's text represents.
5.1. Markup vs. character data
The allowable UCS character sequences in a decoded document fall into two main categories: markup and character data. The character data is at the very least a representation of data, and often is in fact literal data. The markup models that data as a tree, annotates the document with comments, provides information to an XML parser, declares and refers to entities, and declares certain valid logical structures for all documents of that type. Most markup is considered to be part of the "logical" contents of a document, but entity and character references are considered "physical" for some reason.
There are several logical structures in an XML document:
- XML Declaration or Text Declaration
- Document Type Declaration
- Processing Instructions
- Comments
- Text (Character Data)
- Elements and their Attributes
- Document Type Definition (DTD)
5.2. The prolog
An XML document must begin with markup called a prolog. A prolog consists of either an XML declaration or a text declaration, optionally followed by a Document Type Declaration, optionally followed by comments or processing instructions. Whitespace may appear after any of these components of the prolog.
A document entity's prolog begins with an XML declaration and takes the form:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
The XML version is required, but encoding and standalone declarations are optional. The prolog for any entity other than the document entity begins with a text declaration. A text declaration is in the same format as an XML declaration, but it is optional, always contains an encoding declaration, and never contains a standalone declaration.
In an XML declaration, the encoding declaration is not required, but is recommended so that an XML parser can be sure it is decoding the document correctly. Without an encoding declaration, the parser must rely on a default heuristic for determining the encoding, inevitably resulting in an assumption of either UTF-8 or UTF-16. It is considered an error if the document's encoding is not what was declared or assumed. So for example, if the encoding is declared to be iso-8859-1, the parser should reject it if any bytes in the 0x80..0x9F range are encountered, because those bytes do not exist in iso-8859-1.
Although it is allowed to have any value, an encoding declaration should use the name of a
character map as defined by the Internet Assigned Numbers Authority (IANA) in their official
list of "character set" names,
or else a made-up name beginning with "x-". The encoding name is case insensitive.
5.3. Character data
Character data can exist in one of two forms: parsed or unparsed. If it is parsed, then it is
a PCDATA section and the UCS characters can be included in the document directly, provided they
have instances of the markup delimiters < > and & escaped using entity
references, like so:
1 & 2 are < three
In general, ">" does not have to be escaped, but it is good practice to escape it
for the benefit of humans who might be looking at the character data. It is also good practice, and
sometimes necessary, to escape """ and "'" in attribute values.
If a section of character data is to be unparsed, then it is a CDATA section and must be enclosed in markup of the form:
<![CDATA[1 & 2 are < three]]>
People are often misinformed about what a CDATA section actually is. It is just a
convenience for the document author, saving them the trouble of escaping data upon
input. It does not mark a span of text with a "Dear Application, please preserve
me all the way through to output, if you can" flag. Rather, it merely says "Dear XML
Parser, if you see something in here that looks like markup, it's not really markup.
Please report it to the Application as ordinary character data, as if
'<' and '&' had been written as
'<' and '&'." Using a CDATA section does not really
buy anything other than convenience, and it does nothing to make XML a good vehicle for
transporting other markup, unless such markup is never going to be treated as markup ever again.
5.4. Elements and attributes
Character data is divided into named chunks called elements and attributes. Although the XML 1.0 Recommendation does not dictate semantics for these structures, it does imply that they define a hierarchy - a tree of data with a root, branches and leaves. It also places restrictions on attributes such that each attribute can only be a name-value pair that is associated with an element, thereby implying that an attribute is a granular, inherent property of an element.
An element or attribute can have any name that begins with a letter, underscore or colon and otherwise contains only certain other characters (letters, digits, periods, hyphens, underscores, colons, combining characters or extenders). Names beginning with the case-insensitive sequence 'xml' have special meaning. An XML element's name is its type. All elements with the same name are of the same type (this word is used a lot in the spec, so it's good to know what it means). Two attributes with the same name cannot be associated with a single element.
An element is a container for its contents, which can be character data, more elements, or both, in any combination. An XML document must have exactly one root element, also known as the document element. All character data and other elements must be contained within the document element. A parent-child relationship exists between an element and the elements contained within it.
If an element has no contents, then it is "empty" and is denoted with an empty-element tag of the form:
<elementName/>
If an element has contents, then the contents are bounded by a start tag and end tag, like this:
<elementName>this character data is the contents</elementName>
When other elements are in the contents, start and end tags must not overlap.
<greeting>Hello <name>Jane, how are you?</greeting></name>
<greeting>Hello <name>Jane</name>, how are you?</greeting>
An attribute that is associated with an element is inserted in the element's start tag next to the name of the element. The name of the attribute is given, along with its value in single quotes (ASCII apostrophes, actually, not curly quotes) or ASCII double quotes. Double quotes are most common.
<greeting type="informal">Hey Dude! What up?</greeting>
<greeting type='informal'>Hey Dude! What up?</greeting>
If an attribute value contains the same kind of quotes that are quoting the entire value, then those quotes in the value must be escaped.
<movie name='Rosemary's Baby'/>
Attribute values are not the best place to store just any character data, because an XML parser will not interpret the values exactly as they appear in the document. When the document is read by an XML parser, the attribute values will be subjected to whitespace normalization, which in this case means that sequences of whitespace characters (space, tab, linefeed, or carriage return) will be removed from the beginning and end of the value, and consecutive sequences of whitespace elsewhere in the value will be replaced by a single space character.
An XML document can be annotated with comments, as long as those comments are separate from other markup. An XML parser may choose to ignore comments. Text inside the comment does not need to be escaped with entity references, but a sequence of two hyphens is disallowed within the comment.
<!--this is a comment-->
<anElement>hello <!--this is another comment--> world</anElement>
5.5. Processing instructions
Looking very much like the prolog is a bit of markup called a processing instruction. It provides a mechanism for an XML parser to pass information to an application via the document, but it is not considered part of the document's data. It takes the form:
<?foo bar?>
where foo is the target, an identifier for the application to which the instruction is directed.
The target can optionally be formally declared in the DTD via a notation declaration. Any number of
whitespace-separated characters that follow the target, up to the '?>' delimiter, are made
available to the application. Processing instructions are not used that often.
<?xml-stylesheet href="style.css" type="text/css"?>
In this example, xml-stylesheet is the target (presumably this is meaningful to the application), and the underlined string is the instruction. This instruction might be said to contain "pseudo-attributes" because it resembles a series of attributes, but it is just a single opaque, meaningless string, as far as the XML parser is concerned. This string will be interpreted by the application, not the parser.
5.6. The Document Type Definition (DTD)
XML 1.0 provides for a logical structure called the Document Type Definition, or DTD. Like a processing instruction, the DTD is not part of the data in a document. The DTD contains user-defined declarations of what element and attribute names are valid, rules for contents of elements and values of attributes, and the names and locations of entities. All documents written to conform to the rules in a given DTD are considered to be of the same type, hence the name Document Type Definition.
If a document matches all the character encoding and syntax rules defined in the EBNF productions in the XML 1.0 Recommendation, then it is well-formed and can be read by any XML parser. If a document also matches the rules defined in a DTD and the validity constraints imposed by the XML 1.0 Recommendation, then it is valid.
A validating parser is required to check for well-formedness and report validity violations in an entire document, including parsed entities and the complete DTD. A non-validating parser is required to check for well-formedness only in the document entity and the internal DTD subset, and does not need to report any validity violations. A non-validating parser is also not required to read and get replacement text from external parsed entities, but it must inform the application where references to such entities occur.
5.6.1. DTD syntax
XML DTDs use an SGML-inherited syntax to define a frustratingly limited vocabulary for documents. There are a lot of subtle rules to follow when writing DTDs and the only good reference is the XML spec itself, so this tutorial will not go into too much detail.
The declarations in an XML DTD consist of a mixture of tokens and EBNF constructs, inside what look like element tags (but aren't).
5.6.2. DTD syntax: entity declarations
One major kind of declaration is for entities. Each entity is declared with an indicator of whether it is a parameter or general entity, its name, and, depending on whether it is internal or external, a literal entity value in quotes (if internal), or an identifier for where the replacement text can be found (if external and parsed):
<!ENTITY whoa "WHOA!">
<!ENTITY baby SYSTEM "baby.txt">
<!ENTITY % my-DTD-fragment SYSTEM "https://foo.net/path/to/my.dtd">
<!ENTITY % standard-DTD PUBLIC "//W3C-Gobbledygook/1.0">
These examples say that there is a general entity named 'whoa' with replacement text 'WHOA!'; a general entity named 'baby' whose replacement text can be found in the file named 'baby.txt'; a parameter entity (denoted by the percent sign) named 'my-DTD-fragment' whose replacement text can be found at the location identified; and a parameter entity named 'standard-DTD' whose replacement text can be found at a location that the XML parser should know where to find, based on the public identifier given.
An XML parser will determine an internal entity's replacement text by replacing character references and parameter entity references it finds in the literal entity value (the quoted string in the entity declaration). Therefore, the built-in entities, if declared, must look like the following:
<!ENTITY lt "&#60;">
<!ENTITY gt ">">
<!ENTITY amp "&#38;">
<!ENTITY apos "'">
<!ENTITY quot """>
If a DTD or part of a DTD is in an external entity, the entity's replacement text should begin with a text declaration, but is not required to.
External unparsed general entities are handled a little differently. Processing them is the responsibility of the application; the XML parser's responsibility ends with the reporting of information about the entity. Some information about the entity's internal format must be declared after the identifier that indicates the entity's location:
<!ENTITY selfPortrait SYSTEM "me.jpg" NDATA JPEGformat>
<!NOTATION JPEGformat SYSTEM "http://www.jpeg.org">
The presence of the NDATA token indicates that the entity is unparsed. The arbitrary name following it is just a key to the notation declaration. The notation declaration just pairs the name with an identifier that the application should recognize as a cue for how to handle the entity. Notation declarations have additional applications, described below in the section on attribute declarations.
The only place in an XML document where an unparsed entity can be referenced is in the value of an attribute that has been declared to be of type ENTITY or ENTITIES. The entity name is the attribute value; no delineation with "&" and ";" is needed.
5.6.3. DTD syntax: element declarations
Another major kind of declaration is for elements:
<!ELEMENT greeting ( #PCDATA | name )*>
This says: An element of type 'greeting' exists (i.e., there can be elements named
'greeting'). The asterisk indicates that there can be zero or more instances of whatever
precedes the asterisk, which in this case is the grouping (denoted by parentheses) of parsed
character data (denoted by the token #PCDATA) or (denoted by the vertical bar) an element of
type 'name'. The element type 'name' must also be declared, since it was mentioned. This will do:
<!ELEMENT name ( #PCDATA )>
If the DTD contained those two element declarations, then the following document would be valid:
<greeting>¡Hola, <name>César</name>!</greeting>
In this example, the text before and after the <name> is allowed
because of the #PCDATA in the declaration for the element greeting.
The XML parser would report to the application:
- There is an element named 'greeting'.
- It contains the character data '¡Hola, ',
- followed by an element named 'name', which contains
- the character data 'César'.
- After that 'name' element, the 'greeting' element contains the character data '!'.
There is a relatively obscure feature of XML that says that a validating parser must notify the application when the DTD says that an element can contain only element content (no PCDATA). The purpose of this notification is so that the application can know whether it is OK to discard any whitespace that might appear in that element.
Continuing with the previous example, let's add a wrapper element called, simply "wrapper":
<!ELEMENT wrapper ( greeting )>
The valid document could then look like:
<wrapper>
<greeting>¡Hola, <name>César</name>!</greeting>
</wrapper>
The XML parser would report to the application:
- There is an element named 'wrapper'.
- It contains the character data '(linefeed)(space)(space)'. This is insignificant whitespace.
- After that, there is an element named 'greeting', which contains
- the character data '¡Hola, ' (note the significant space),
- followed by an element named 'name', which contains
- the character data 'César'.
- After that 'name' element, the 'greeting' element contains the character data '!'.
- Following the 'greeting' element is the character data '(linefeed)'. This is insignificant whitespace.
There is a way for a document author to override this behavior and force an application to recognize all whitespace in an element as being significant, using the xml:space attribute, described below.
5.6.4. DTD syntax: attribute declarations
Another major kind of declaration is for attributes. Attributes can be complicated to declare, so here is a relatively simple example:
<!ATTLIST greeting
type ( formal | informal ) #REQUIRED
length CDATA #IMPLIED>
This says that for the element of type 'greeting', there are two attributes named 'type',
which is required to be present, and 'length', which is optional (denoted by the #IMPLIED token).
The 'type' attribute can have a value consisting of a special class of parsed character data
called an NMTOKEN, which must be in this case one of either 'formal' or 'informal'. The
'length' attribute can have a value consisting of any parsed character data, denoted by the
CDATA token. CDATA is just a token and should not be confused with an unparsed CDATA section in
the document.
Attribute value types can be:
CDATA(any parsed character data; may be further restricted by a default value);NMTOKEN(any character sequence matching the production for NMTOKEN);NMTOKENS(a sequence of one or more whitespace-separated NMTOKENs);- An enumerated list of particular
NMTOKENS(as in the example above); ID(any character sequence matching the production for ID and that doesn't repeat in a document);IDREF(an ID sequence that is the same as an attribute of type ID elsewhere in the same document);IDREFS(one or more whitespace-separated IDREF sequences);NOTATION(a character sequence matching the name of a declared notation; see below for explanation and examples).ENTITY(the name of an unparsed entity declared elsewhere in the DTD)ENTITIES(a sequence of one or more whitespace-separated ENTITY)
It is also possible to declare default values for attributes by putting the quoted value in
place of the #REQUIRED or #IMPLIED token. The attribute can be declared as always existing
(even if it is omitted from the document) and always having the default value by preceding the
default value with the token #FIXED.
The XML 1.0 Recommendation defines two attributes that have special meaning and that can be associated with any element. When these special attributes are used and the document is being checked for validity, the spec requires that they be declared in the DTD.
- The special CDATA-type attribute named xml:space, as mentioned before, must be declared as having either the value "preserve" to indicate that the application should always consider any whitespace in the element contents to be significant character data, or the value "default" to indicate that the application does not need to consider the element's whitespace to be significant.
- The special CDATA-type attribute named xml:lang associates an element's contents with a human language. More information about its valid values and when to use it is in the next section, below.
There is also a rarely-used declaration called a notation, which creates a name-location pair
that can be used to signal to an application that a parsed character data section is to be
interpreted as having some kind of additional encoding, such as Base64 or PostScript. It can
also be used to describe the target for a processing instruction. Here is an example declaring
two notations, an element, and an attribute of type NOTATION. The possible value of the attribute
is one of the two declared notation names:
<!NOTATION ps PUBLIC "Postscript Level 3">
<!NOTATION vrml SYSTEM "http://www.web3d.org/">
<!ELEMENT FormattedData ( #PCDATA )>
<!ATTLIST FormattedData
Format NOTATION ( ps | vrml ) #REQUIRED>
An element conforming to these declarations might look like this:
<FormattedData Format="ps">
gsave
112 75 moveto 112 300 lineto
showpage grestore
</FormattedData>
5.7. The xml:lang attribute
As mentioned above, xml:lang is a special attribute that allows document authors to flag element content as being related to a particular language.
5.7.1 Acceptable values for xml:lang
According to the XML 1.0 Recommendation and its errata, the value of an xml:lang attribute must be an (XML) LanguageID. A LanguageID is normatively defined by IETF RFC 1766, "Tags for the Identification of Languages". The XML spec muddles this quite a bit by trying to provide a summary of what RFC 1766 says, and they botched their references, so it's rather confusing.
RFC 1766 provides several ways of constructing a LanguageID.
The simplest method is to use an ISO 639:1988 2-letter language code. These codes are case-insensitive but are typically lowercase. Examples: "en" or "fr". Reference: http://ftp.std.com/obi/Standards/ISO/ISO_639.
ISO 639 has been updated a number of times since 1988 and is now in 2 parts, ISO 639-1 for the 2-letter codes and ISO 639-2 for 3-letter codes. It has been argued that due to XML 1.0's normative reference to RFC 1766 and that document's requirement that it be superseded to accommodate updates to ISO 639, we are technically stuck with using the 1988 codes. In a post to the IETF Languages mailing list on 02 Aug 2000, Harald Tveit Alvestrand, the author of RFC 1766, said "The intent of RFC 1766 and the current draft is that the lists referred to are the published versions + any later changes. I refuse to put in references to unpublished documents, but that's my only religion on the matter; replacement text is welcome."
2. ISO 639 doesn't identify some obscure languages, so RFC 1766 also allows IANA registered language identifiers to be used. These codes either begin with "i-" followed by 3 to 8 letters identifying a language, or they begin with an ISO 639 2-letter language code, followed by a hypen and 3 to 8 letters denoting the region in which the langauge is used (useful for identifying regional dialects). These codes are case-insensitive but are typically lowercase. Examples: "i-navajo" (Navajo) or "zh-yue" (Cantonese). Reference: http://www.isi.edu/in-notes/iana/assignments/languages/tags.
3. RFC 1766 says you can make up your own identifiers, as long as they begin with "x-" or "X-". Example: "x-piglatin".
4. RFC 1766 allows 2-letter country codes to be appended to the 2-letter language codes, in the same way the IANA language tags append 3-to-8 letter region codes. When a 2-letter suffix is being used, it *must* be a 2-letter country code from ISO 3166:1988. These codes are case-insensitive but are typically UPPERCASE. Examples: "en-US" or "en-GB" or "fr-CA". Reference: https://en.wikipedia.org/wiki/ISO_3166.
As with ISO 639, ISO 3166 has been updated a number of times and is now ISO 3166-1, but you're only allowed to use the 1988 codes.
5. You can go on tacking on as many additional suffixes onto the end as you want, after the 2-letter country code from ISO 3166:1988. If you didn't use a 2-letter country code, you can still append any suffixes you want, as long as the first one isn't 2 letters.
5.7.2 When (not) to use xml:lang
1. Use the xml:lang attribute as a descriptive supplement to elements that contain language-specific character data, whether that character data is element content or in the element's other attribute values. xml:lang is intended to apply to everything contained within the element, so it's not necessary to use it on all sub-elements if it has already been declared.
If xml:lang is used in an element, it must be declared in the DTD, like any other attribute. The "xml:" prefix does not have to be declared in an xmlns:xml attribute, though; the XML Namespaces recommendation says that xml: is by default bound to a particular namespace.
Example:
<?xml version="1.0"?>
<!DOCTYPE dialog [
<!ELEMENT question (#PCDATA)>
<!ELEMENT answer (#PCDATA)>
<!ELEMENT dialog (question,answer)>
<!ATTLIST question
by CDATA #IMPLIED
xml:lang CDATA #IMPLIED>
<!ATTLIST answer
by CDATA #IMPLIED
xml:lang CDATA #IMPLIED>
]>
<dialog>
<question by="Limey Brit" xml:lang="en-GB">What colour is your tea, mate?</question>
<answer by="American Dork" xml:lang="en-US">Tea comes in different colors?</answer>
</dialog>
Here is a demonstration of the inheritance principle. The entire dialog is English, and it may not be necessary to differentiate between dialects. Only the dialog element contains the xml:lang attribute, but the attribute implies that the entire contents of the element are in English, so an application will likely say that the language of the question and answer elements is English in each case:
<?xml version="1.0"?>
<dialog xml:lang="en">
<question by="Limey Brit">What colour is your tea, mate?</question>
<answer by="American Dork">Tea comes in different colors?</answer>
</dialog>
2. Try to only use xml:lang as a descriptor of language-specific content of data elements. In situations where, say, a user has made a language choice in a UI and you want to record that choice in an XML document, you should make up your own element for this purpose. When the language itself is a significant piece of data rather than just a property of one other granular piece of data, you need to use something other than xml:lang.
Example:
<?xml version="1.0"?>
<Site>
<SiteProperties>
<SiteLanguage>fr</SiteLanguage>
...
</SiteProperties>
<SiteData>
<MerchantName>Violet's Violets</MerchantName>
<Slogan xml:lang="en-US">We aim to please</Slogan>
<Slogan xml:lang="fr-CA">Parlez-vous? Oui!</Slogan>
...
</SiteData>
</Site>
In this example, the application could select the correct Slogan for inclusion in the site by comparing the SiteLanguage with the xml:lang attributes. In XSLT/XPath, this is trivial, using the lang() function, which looks for ancestors with xml:lang and ignores suffix disparities (so a test for "fr" would match "fr-CA").
In practice, for most applications, using just the ISO 639:1988 2-letter codes, or those codes plus the ISO 3166:1988 2-letter country code suffixes, is more than sufficient.
Acknowledgments:
This work was based upon...
- The Unicode Standard, Version 3.0; ISBN 0-201-61633-5, which has various explanatory sections that apply to chapter 2 of this tutorial
- Unicode Technical Report #17, which goes a bit further than chapter 2 and has excellent diagrams explaining the relationship between abstract characters and glyphs
- Kenneth Whistler @ Sybase, who proofread a draft of chapter 2 and suggested a few edits for accuracy
- XML 1.0, the W3C Recommendation annotated by Tim Bray.